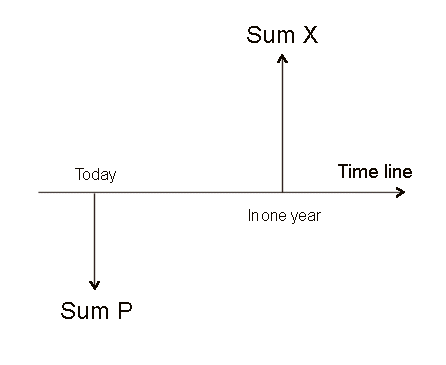Finance with a review of accountingRandomness of a security, risk-return graph, systematic risk and specific risk |
|||||
|
|
|
||||
|
The steps in probability theory Probability theory as a toolbox for finance Example of a security Randomness of a security Random walks The three approaches to the variability of prices The risk return graph Systematic risk and specific risk |
|||||
|
The steps in probability theory
The presentation of probability theory requires several steps. If we miss no step it is reasonably easy to understand, and to use, but, if we miss a single step, it may become extremely confusing. So, here is a little review of the steps :
Probability theory as a toolbox for finance With these elements of probability theory, we have tools to approach the study of investments (financial investments into securities, and physical investments into projects), which will produce unsure cash flows in the future. With the technique of discounting (which we will study in the next lesson) we will be able to attach a value today to future cash flows. We will be able to compare various investments. We study essentially two situations :
The two situations can be memorized with these two pictures :
Finally, we shall be concerned with profitabilities of securities. If we buy a security S today, for a price P, and S produces a cash flow X, in one year (and X is a random variable), then the profitability that we will make in one year is
R is a random variable, with possible outcomes, with a mean, with a variance and a standard deviation. E(R) is denoted r. If need be, we use the more specific notation rS. It is the expected profitability of the security S. Sometimes, for short, we call it, abusively, the profitability of S. Standard deviation of R is denoted σ, or, if necessary, σS. σS is, by definition, the risk of S. In other words, in finance, the risk of a security is the standard deviation of its profitability. Securities with zero risk are called risk free securities. At present, in the euro zone, they are sold with a discount of 2% on their future value. More risky securities are sold for less. Exercise :
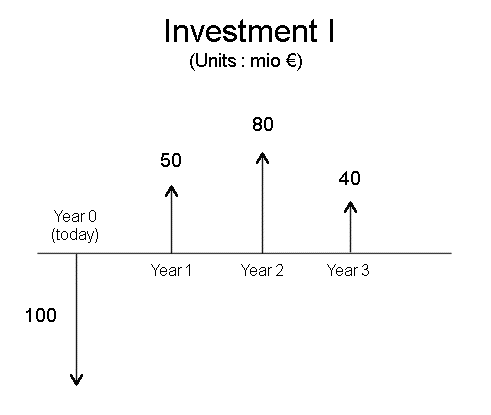
We will extend the concept of profitability to a stream of future cash flows. For several cash flows, the usual notations are these : initial investment : C0 (akin to P in the case of one security) future cash flows : C1, C2, C3, ... , Cm, if there are m years. These extend the unique cash flow X of the one year case. And, like X, they are random variables. But, if we don't specify it otherwise, we shall directly consider the expectations of the future cash flows. And the Ci's will be expectations. A slight difference between P and C0 : usually, for a security S there is a market price today, that's what we call P. And we shall see how P can be computed. Most of the time, for a physical investment I which will produce a stream of future cash flows, there is no market price. But we have to invest C0 to produce the stream of future cash flows. Sometimes it will be a good deal for us, sometimes it won't. This is what we shall study in the next few lectures.
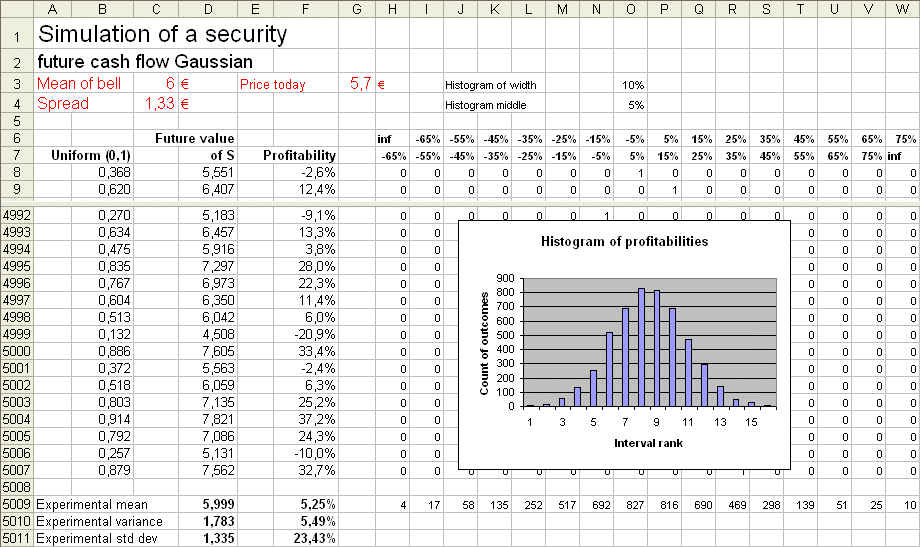
Consider a security S, with a present price P, and with a value in one year X. We shall work with a numerical example : assume X is normally distributed with mean E(X) = 6€ and standard deviation σ(X) = 1,33..€. If P, the price we pay today for S, is 5,7€ then our profit will be X - 5,7, and our profitability will be (X-5,7)/5,7. Depending upon the outcome of X, we will actually make a profit or not. Our expected profitability will be E[ (X-5,7)/5,7 ] = E [ X/5,7 - 1 ] = E(X) / 5,7 - 1 = 5,26%. Check with a simulation :
This Excel sheet presents the simulation of 5000 replications of the experiment producing the value of S in one year : we produced 5000 outcomes of X, and therefore 5000 outcomes of R = (X - 5,7)/5,7. E(X) = 6, and the experimental mean is 5,999 σ(X) = 1,333 and the experimental std dev is 1,335. E(R) = 5,26%, and the experimental mean is 5,25% σ(R) = σ(X/5,7 - 1) = σ(X)/5,7 (because a translation of an RV does not change its std dev, and a rescaling rescales the std dev) = 23,39%, and the experimental std dev = 23,43%. In order to understand finance, we must understand perfectly what this simulation does.
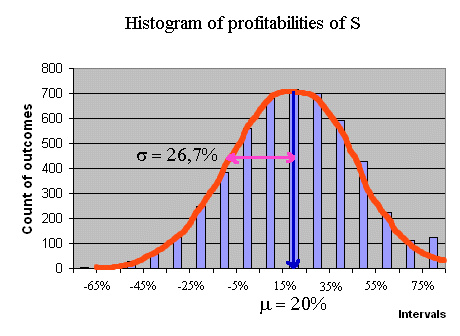
Suppose, now, that to purchase S, today, we pay a price P = 5€ With this price P, the expected profitability of S is 20% (= (6-5)/5). And the standard deviation of the profitability is 1,333/5 = 26,7%. This can be checked again with a simulation. You are strongly encouraged to construct the simulation and check these figures by yourself.
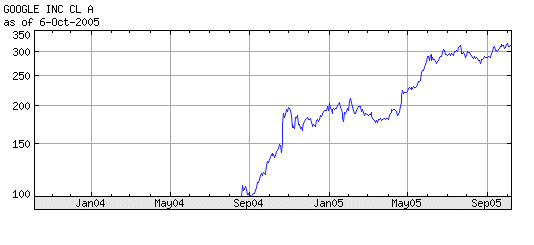
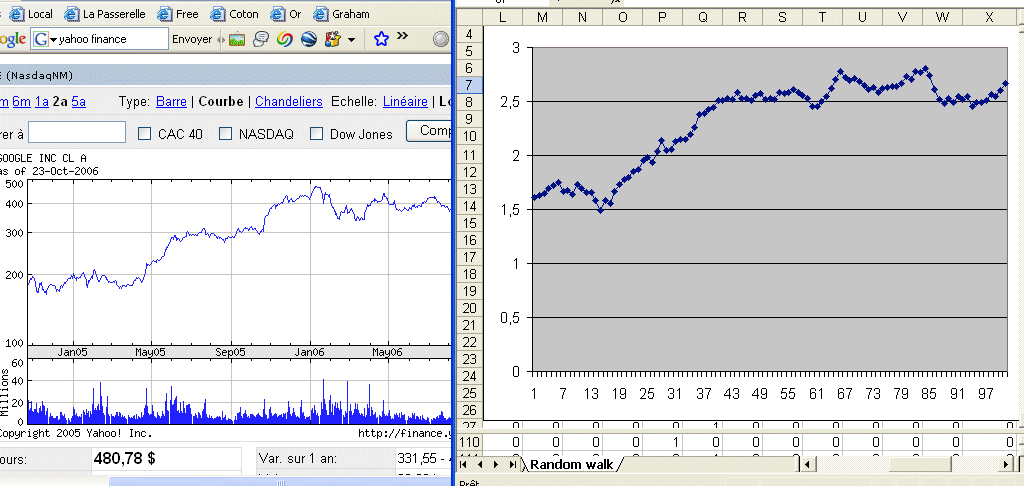
Let's consider a security S, with a price P today. Finance considers its value X in one year as a random variable. It will have an outcome x. This x will be the price of S in one year. Then S will have a value in two years, which is a random variable, etc. The sequence of yearly prices is not a series of outcomes of one random variable, because they are related to each other. Finance considers the series of profitabilities as a series of outcomes of one random variable, the random variable R. The series of prices is called a random walk. The multiplicative step to go from one year to the next is a random variable (1 + R). In fact, if we look at Google prices over the last year we see readily that the prices are not outcomes of one random variable :
The first scholar to talk about and study random walks in finance was Louis Bachelier, 1900. His doctoral work did not receive much consideration at the time, and he got his thesis with an average mark, and then went into obscure teaching positions. Later on his work was rediscovered, in particular by Samuelson, in the early 50's, and became the object of much study. Today Bachelier is considered one of the towering figures of early modern finance. He studied "arithmetic random walks", where one position differs from the previous one by an additive random factor Dn, with a steady normal distribution N(μ, σ). Then he refined his model to an infinitesimal additive component, leading to Brownian motion, and he got very close to the Black-Scholes formula of option theory. Today, the preferred model for stock price evolution is the geometric random walk, where one position differs from the previous one by a multiplicative random factor (1 + Rn), where Rn has a steady normal distribution. A variant model considers that log(Pn+1 / Pn) is normally distributed. In the previous section we have the representation, in a logarithmic vertical scale of the price of Google over time. A question is : is it reasonable to model it has a geometric random walk ? See next section for a discussion.
The three approaches to the variability of prices There are three approaches to the study of the price evolution over time of a given stock.
Here is a comparison of Google prices and a computer generated geometric random walk (both with logarithmic vertical scales) :
It looks like it makes sense to consider that Google prices follow a geometric random walk.
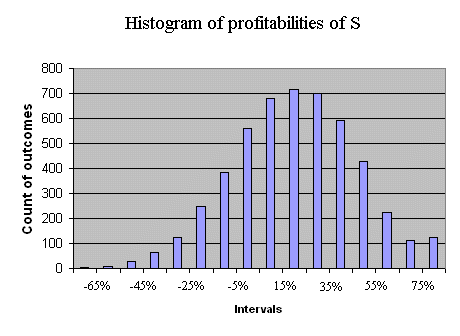
When considering securities traded in the stock market (shares of firms) we will often use the so-called risk return graph : on a graph with axes risk and return, we will position the various securities under study. For instance, let's position the security S with price P = 5€, and a normally distributed payoff X, with E(X) = 6€ and σ(X) = 1,333€. We can compute E(RS) and σ(RS), but let's take the opportunity of this operation to read these two quantities from a histogram obtained from a large simulation. The profitability of S has the following histogram (produced with 5000 outcomes of RS) :
We can read from this graph E(RS) and σ(RS) :
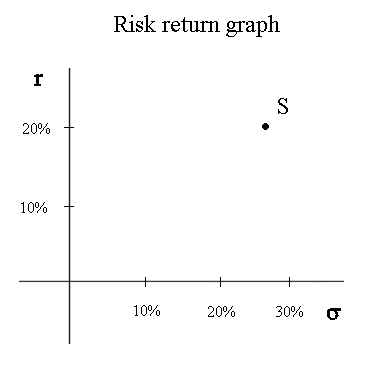
And now we can position S on the risk return graph, like this :
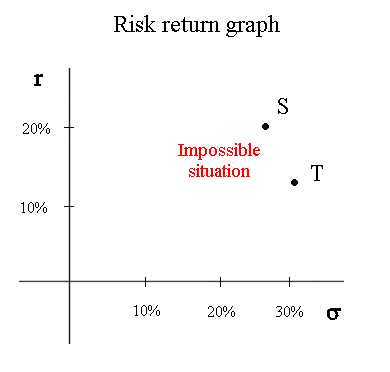
Systematic risk and specific risk We have already briefly mentioned that stocks, in the stock market, have a systematic risk (fundamentally linked to the randomness of the economy) and a specific risk (akin to an extra random quantity added to their future cash flow, with mean zero, and that would be produced by the equivalent of a random generating device). Investors are risk averse concerning systematic risk. They don't care about specific risk because there are ways to eliminate it (more on this later in the course). Consider two securities, S and T, with different systematic risk and no specific risk. Then, if both promise the same expected cash flow in one year, investors will pay less for the riskier one. As a consequence, the riskier one will have a higher expected profitability. This has a consequence on the risk-return graph : if we look only at securities with systematic risk, and no specific risk, It is not possible to have two securities S and T positioned like this :
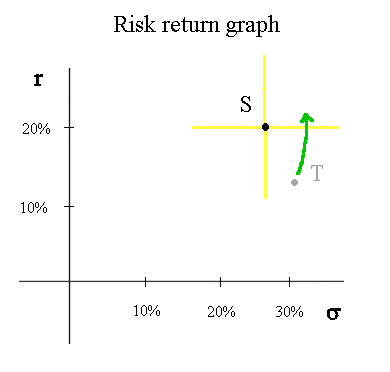
Indeed, if S is a security available in the market with r = 20% and σ = 26,7%, nobody will buy another security T, with less profitability and more systematic risk. So the price of T will decline until its profitability becomes higher than that of S. The point representing T will move to the top and slightly to the right :
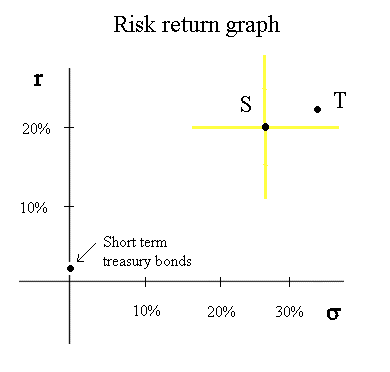
Finally, let's mention and position the risk free security : the short term Treasury bonds (yielding, at present, in Europe, 2%) :
|
|||||